 |
|
|
Our initial description of the system (i.e., Ioannou et al., JoDS 2013) provides examples on how generated data can be used for evaluating matching-related methods. In addition, the VLDB 2018 publication by Ioannou and Garofalakis, provides an example of how the system can be used for generating and using data for the experimental evaluation. The authors evaluated their technique on the real data sets of Cora, CiteSeer, DBLP/ACM, and also used generated data for being able to study the influence of a small set of particular characteristics, such as the number of instances in the collection. More specifically, EMBench++ was used for generating 3 collections with a total of 12 data sets. Each collection had a fixed value on one of the investigated characteristics and an increased number for the other characteristics. The data sets from these collections were used for evaluating various aspects of the introduced technique. The following list provides some of the performed tests:
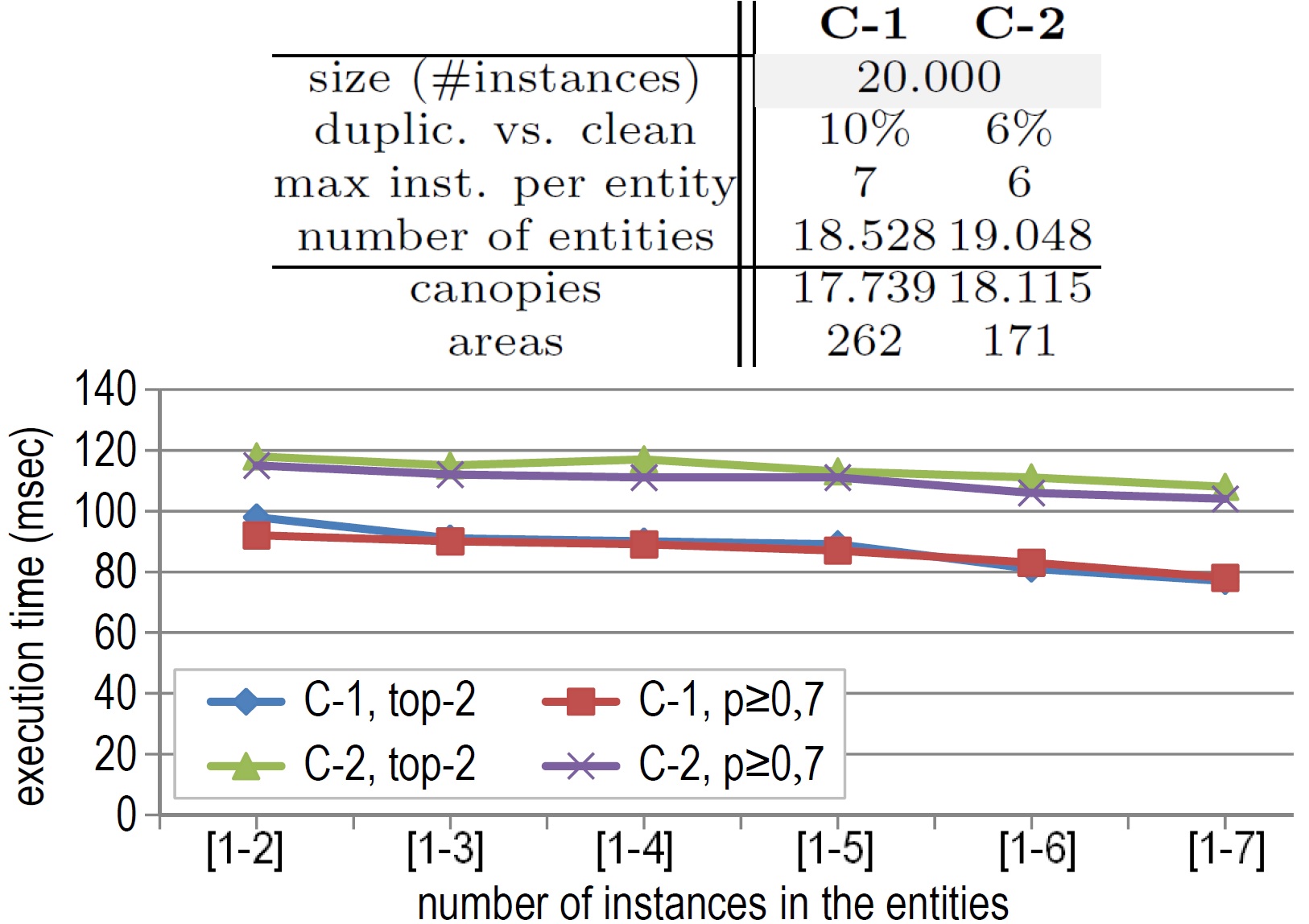
As an example, consider the evaluation result shown in the above figure (originally shown in particular publication). This uses two of the synthetic data sets, namely the C-1 and C-2 data sets. Both data sets contain 20.000 entities but a different number of duplicates with a different ration of duplicated vs. clean entities (i.e., 10% C-1 and 6% for C-2) and different number of maximum instances per entity (i.e., 7 for C-1 and 6 for C-2). The authors performed evaluations for each of these data sets and for each of the two supported query types, which are top-k and threshold. Then, they reported execution time (i.e., efficiency) according to the number of maximum instances per entity. |
|||
| Last modified: May 2018, Page maintained by: Ekaterini Ioannou, Yannis Velegrakis | ||||